Quando o lag sobe, a reação mais comum é olhar para broker, CPU, disco ou rede.
Só que, muitas vezes, o cluster está saudável.
No post anterior, falamos que lag alto é sintoma, não diagnóstico. Um dos motivos mais traiçoeiros para isso é a hot partition.
Conceito: o que é uma hot partition?
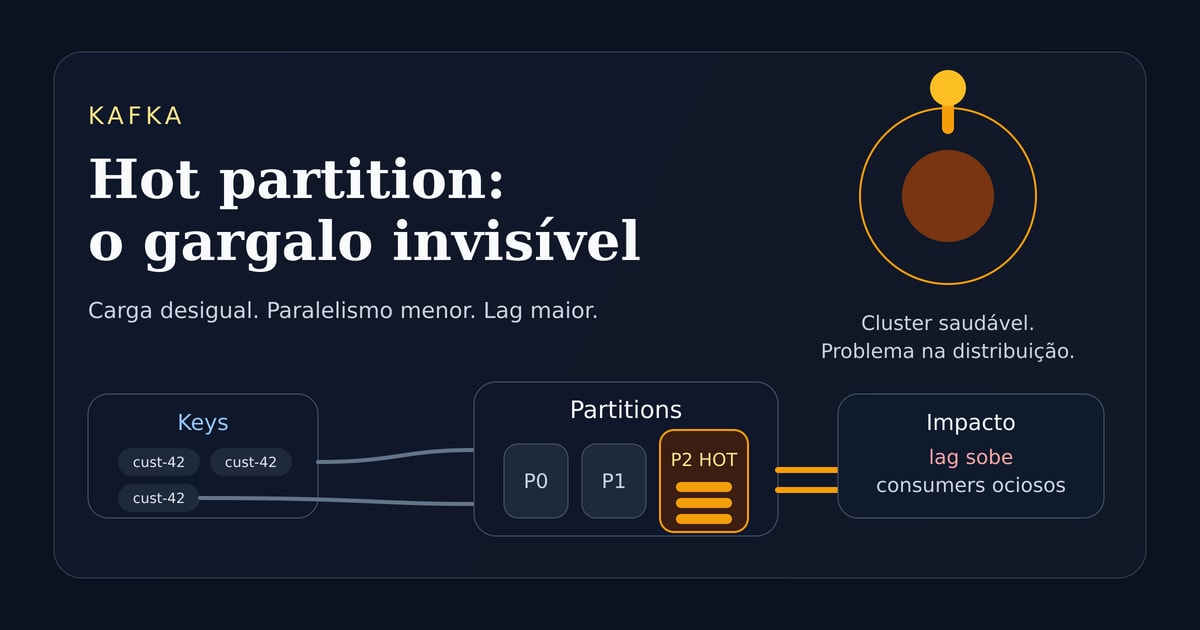
Hot partition é quando uma partition recebe muito mais mensagens do que as outras.
Na prática, isso cria um gargalo silencioso.
O tópico pode ter várias partitions. O consumer group pode ter várias instâncias. O cluster pode estar estável.
Mesmo assim, o throughput real fica limitado pela partition que concentrou a maior parte da carga.
Esse problema normalmente nasce de duas coisas:
- escolha ruim de key
- distribuição desigual do tráfego entre os valores dessa key
Em outras palavras: o Kafka está pronto para paralelizar, mas a forma como os eventos foram distribuídos impede que esse paralelismo aconteça de verdade.
Por que isso acontece
As causas mais comuns são bem menos exóticas do que parecem:
-
Key com baixa cardinalidade: Usar algo como
status,tipoEventoouregiaoparece simples, mas poucos valores possíveis significam poucas rotas reais de distribuição. -
Key de negócio com tráfego concentrado:
customerId,sellerIdouaccountIdpodem fazer sentido para preservar ordem. O problema é quando poucos IDs concentram volume muito acima da média. -
Crescimento de volume sem revisão da estratégia: A key funcionava bem no início, mas o sistema cresceu, alguns clientes passaram a movimentar muito mais eventos e a distribuição deixou de ser saudável.
-
Ordem tratada como requisito absoluto: Às vezes a key é escolhida para preservar ordem por entidade, mesmo quando o processamento não exige isso em todos os casos. O custo aparece depois, em forma de gargalo.
Cenário real
Imagine um tópico de pedidos com 12 partitions.
O producer usa customerId como key. A decisão parece correta: eventos do mesmo cliente ficam na mesma partition e a ordem é preservada.
Agora entra o detalhe que quase sempre aparece só em produção:
3 clientes enterprise geram 70% do volume do tópico.
Resultado:
- quase todas as mensagens desses clientes caem sempre nas mesmas partitions
- essas partitions acumulam backlog
- as demais partitions ficam com pouco trabalho
- o consumer group parece bem dimensionado, mas o throughput total fica preso nos mesmos pontos de estrangulamento
Outro exemplo comum é usar status como key:
PENDINGPROCESSINGFAILED
A cardinalidade é tão baixa que a concentração de carga deixa de ser risco e vira consequência natural.
Como detectar o problema
O erro mais comum aqui é olhar apenas o lag total do tópico.
Lag agregado ajuda a perceber atraso. Não ajuda a entender distribuição.
Para identificar hot partition, o ideal é observar o comportamento por partition.
Sinais fortes:
- lag alto concentrado em poucas partitions
- outras partitions com lag baixo ou zerado
- alguns consumers muito mais ocupados do que outros no mesmo group
- throughput abaixo do esperado mesmo com brokers saudáveis
- mais pods sem ganho proporcional de consumo
Perguntas úteis durante a investigação:
- O lag está espalhado entre todas as partitions ou concentrado em 1 ou 2?
- As partitions com maior lag também recebem mais mensagens por segundo?
- Existe alguma key dominando grande parte do volume?
- O número de consumers já está próximo do número de partitions e, ainda assim, o atraso continua?
Essa distinção é importante:
- se todas as partitions acumulam lag, o problema pode ser capacidade insuficiente do consumer
- se o lag está concentrado em poucas partitions, a suspeita de hot partition fica muito mais forte
Hot partition e consumer lento podem coexistir. Mas são problemas diferentes e exigem decisões diferentes.
Por que mais consumers nem sempre resolvem
Quando o lag sobe, aumentar a quantidade de consumers parece a resposta mais óbvia.
Nem sempre é.
No Kafka, o paralelismo é limitado pelo número de partitions. Mas, na prática, ele também é limitado por como a carga está distribuída entre elas.
Se 80% das mensagens caem em 2 partitions, são essas 2 partitions que definem o ritmo de consumo.
Adicionar mais consumers só ajuda quando existe trabalho distribuído para eles processarem.
Se a carga continua concentrada, você escala o grupo e continua esperando pelas mesmas partitions quentes.
Essa é uma dúvida comum: "não daria para colocar mais threads para consumir a partition sobrecarregada?"
Em um mesmo consumer group, não.
Uma partition só pode ter um consumer ativo por vez. Isso significa que o paralelismo no Kafka acontece entre partitions, não dentro da mesma partition.
Se o gargalo está concentrado em uma partition quente, mais threads no grupo não destravam esse ponto específico.
O que até pode existir é paralelizar o processamento depois da leitura, dentro da aplicação. Mas isso já é outra estratégia, com custo real de complexidade: controle de ordem, commit, retry e tratamento de falhas ficam muito mais delicados.
Ou seja: não é "mais thread no Kafka". É uma mudança no desenho do processamento.
Como pensar uma boa key
A melhor key não é necessariamente a mais intuitiva do ponto de vista de negócio.
Antes de escolher, vale responder:
- Eu realmente preciso de ordem por essa entidade?
- Essa key tem cardinalidade suficiente?
- O tráfego tende a se distribuir bem entre os valores possíveis?
- Existem poucos clientes, contas ou parceiros que podem concentrar volume?
- Estou otimizando para semântica de negócio, para distribuição, ou tentando fazer as duas coisas ao mesmo tempo?
Uma boa key costuma ter estas características:
- cardinalidade razoável
- distribuição previsivelmente equilibrada
- alinhamento com a necessidade real de ordenação
- comportamento sustentável quando o volume crescer
Alguns alertas práticos:
- chave de negócio nem sempre é boa chave de particionamento
- poucos valores possíveis quase sempre indicam risco
- uma key que funciona em baixo volume pode virar gargalo em escala
- preservar ordem demais pode custar throughput demais
Estratégias para evitar ou reduzir hot partitions
Não existe fórmula mágica, mas algumas decisões ajudam bastante:
- revisar a key com base em distribuição real, não só em semântica
- medir cardinalidade e concentração antes de consolidar a estratégia
- evitar atributos com poucos valores possíveis como chave principal
- separar, quando possível, necessidade de ordenação e necessidade de balanceamento
- reavaliar o número de partitions junto com a estratégia de distribuição
Vale um cuidado importante:
Aumentar o número de partitions não corrige sozinho uma key ruim.
Se a lógica de particionamento continua concentrando tráfego nas mesmas chaves, você apenas aumenta o espaço disponível para uma distribuição que continua desigual.
Em alguns cenários, compor a key com mais de um atributo pode melhorar o balanceamento. Em outros, a melhor decisão é aceitar menos ordenação por entidade em troca de mais capacidade real de processamento.
Arquitetura é tradeoff. O erro é fingir que esse tradeoff não existe.
Checklist rápido de investigação
Antes de culpar o broker ou escalar o consumo, vale passar por estas perguntas:
- O lag está em todas as partitions ou só em algumas?
- As partitions com maior atraso também concentram mais produção?
- Existe concentração de volume em poucas keys?
- O consumer group está escalado, mas o throughput real continua baixo?
- A escolha da key foi validada com padrão real de tráfego ou apenas com regra de negócio?
Regra de ouro
Hot partition é um gargalo arquitetural, não um azar operacional.
Quando a distribuição da carga é ruim, o Kafka pode continuar saudável e, ainda assim, o paralelismo real praticamente desaparecer.
Particionamento não é detalhe de implementação. É decisão de arquitetura.
Seu time hoje conhece a distribuição real das keys dos tópicos mais críticos, ou só descobrimos isso quando o lag explode?