O sistema cresce, o volume sobe e o comportamento começa a ficar estranho.
Alguns consumers ficam sobrecarregados. Outros quase sem trabalho. O lag aparece onde antes tudo parecia estável.
Nessa hora, muita equipe percebe tarde demais que o número de partitions nunca foi um detalhe.
Foi uma decisão de arquitetura tomada cedo, às vezes no chute.
No post anterior, falamos sobre como a key define ordem, distribuição e paralelismo. O próximo passo natural dessa conversa é entender que o número de partitions define o teto estrutural dessa escala.
O que a partition realmente representa
Partition é a unidade básica de armazenamento e leitura paralela de um tópico.
Na prática, ela também define o limite máximo de paralelismo de um consumer group.
Se um tópico tem 6 partitions, esse group consegue ter, no máximo, 6 consumers ativos lendo em paralelo.
Isso significa duas coisas bem simples:
- se existirem 10 consumers no group, 4 vão ficar ociosos
- se existirem só 2 consumers, apenas 2 fluxos de leitura vão absorver toda a carga
Ou seja: o número de partitions define o teto. O número de consumers define o quanto desse teto você realmente ocupa.
Esse ponto costuma gerar erros comuns de configuração.
Um deles é aumentar concurrency como se isso, por si só, criasse mais paralelismo real.
Se o tópico tem 6 partitions, configurar concurrency=10 não cria 10 fluxos reais de leitura.
Continua existindo espaço para apenas 6 consumers ativos naquele group.
Os excedentes ficam ociosos e ainda aumentam ruído operacional em escala, rebalance e diagnóstico.
Outro erro é olhar só para o número de pods e esquecer que concurrency também entra nessa conta.
Se um tópico tem 12 partitions, 3 pods com concurrency=2 significam 6 consumers no group.
Ainda existe espaço para crescer.
Mas, se o deploy sobe para 6 pods com concurrency=2, o group chega a 12 consumers ativos e encosta no teto do tópico.
Qualquer pod extra acima disso não aumenta o paralelismo real.
Só adiciona consumers excedentes, disputando participação sem trabalho para consumir.
Esse é o ponto central:
- partitions definem o teto de paralelismo
- consumer group divide esse trabalho entre os consumers ativos
- throughput real depende dessa divisão fazer sentido para o volume do sistema
Por isso, escolher o número de partitions é escolher o espaço real de escala do tópico.
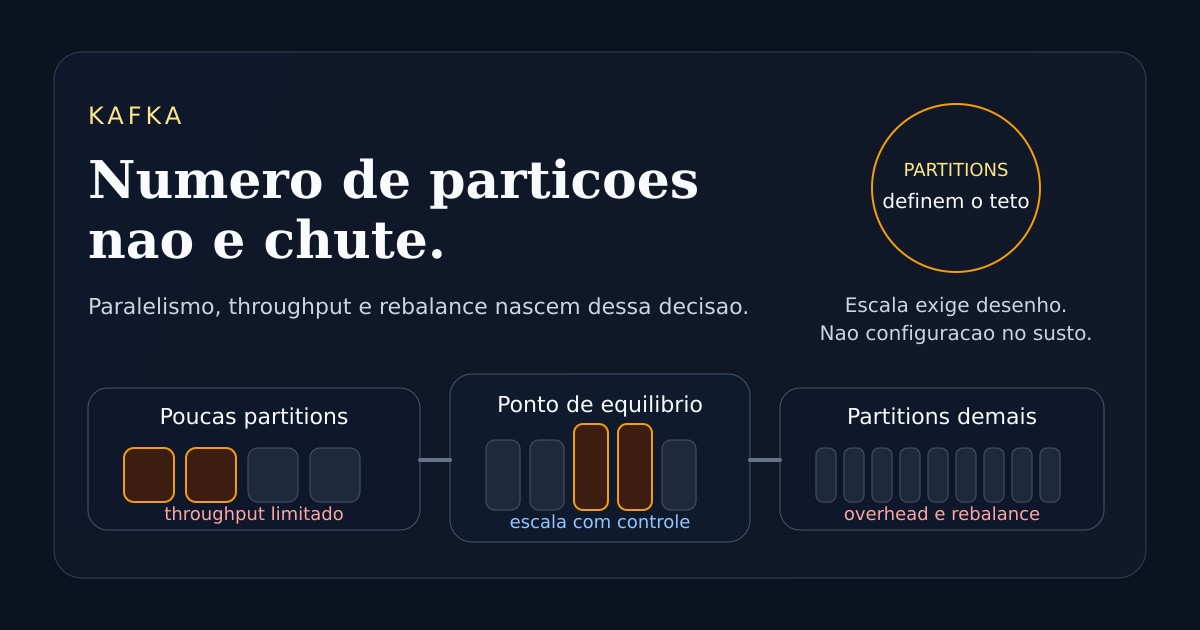
Quando existem poucas partitions
O erro mais comum no início é subdimensionar.
Com baixo volume, tudo parece suficiente.
Mas, quando o tráfego cresce, aparecem sintomas bem conhecidos:
- o throughput fica preso em poucas rotas de consumo
- escalar o número de consumers deixa de ajudar rapidamente
- o lag sobe mesmo com capacidade ociosa fora daquele ponto de gargalo
Na prática, o sistema até tem mais instâncias disponíveis, mas não tem partitions suficientes para ocupá-las.
O resultado é um teto artificial de escala.
Não porque o cluster falhou.
Porque a arquitetura limitou cedo demais o paralelismo possível.
Quando existem partitions demais
O erro oposto também custa caro.
Criar partitions em excesso não significa "estar pronto para crescer".
Significa aumentar o custo estrutural do tópico desde agora.
Mais partitions trazem efeitos reais:
- mais metadados para o cluster gerenciar
- mais custo operacional no armazenamento e na replicação
- rebalances mais demorados
- mais complexidade para operar, observar e ajustar consumo
Isso costuma aparecer em produção quando um group reinicia, escala ou perde instâncias.
Quanto mais partitions estiverem envolvidas, maior tende a ser o trabalho de redistribuição.
Ou seja:
partitions demais não entregam escala de graça.
Elas cobram em overhead, custo e tempo de reação operacional.
Como começar a dimensionar
Não existe número mágico.
Mas existe raciocínio técnico melhor do que "vamos colocar um valor qualquer e depois vemos".
Um bom começo é alinhar o número de partitions ao paralelismo que o sistema realmente deve sustentar.
Vale pensar em perguntas como:
- quantos consumers ativos eu espero usar quando o volume subir?
- qual throughput esse tópico precisa suportar?
- esse volume deve crescer quanto nos próximos ciclos?
- aumentar partitions depois vai ser simples ou vai exigir mudança operacional delicada?
O objetivo não é acertar um número perfeito.
É escolher um número coerente com o paralelismo esperado hoje e com margem razoável para o crescimento previsível.
Decisão boa aqui não nasce de achismo.
Nasce de carga esperada, estratégia de consumo e visão de evolução do sistema.
Existe até uma heurística bem conhecida para esse cálculo, popularizada pela Confluent em um material originalmente escrito por Jun Rao:
partitions >= max(t/p, t/c)
Onde:
té o throughput alvo do tópicopé o throughput medido de produção por partitioncé o throughput medido de consumo por partition
Essa conta é útil como ponto de partida porque força uma conversa mais concreta sobre capacidade real.
Mas ela só funciona bem quando p e c foram medidos no seu contexto, com payload, lógica de consumo e volume próximos da realidade de produção.
Usar a fórmula sem benchmark continua sendo uma forma mais sofisticada de chute.
Escala não aparece por acaso
Kafka entrega escala, mas não por improviso.
O número de partitions de um tópico afeta throughput, paralelismo, rebalance e operação do cluster ao mesmo tempo.
Quando essa decisão é tratada como detalhe, o sistema cresce e o custo aparece em forma de lag, desperdício de capacidade e complexidade desnecessária.
Escalabilidade não é sorte de configuração.
É consequência de design.
Referência técnica
Confluent: How to Choose the Number of Topics/Partitions in a Kafka Cluster?