Ter schema ajuda.
Mas, sozinho, ele ainda não resolve o problema mais perigoso: alguém pode quebrar o contrato mesmo assim.
Um time até modela bem o evento. Outro usa Avro. Um terceiro conhece os modos de compatibilidade. Só que, sem um ponto central de controle, cada serviço ainda pode evoluir o próprio contrato do jeito que achar seguro.
Em produção, isso é pouco.
No post sobre JSON vs Avro, a diferença principal era sair do payload informal para um contrato validável. O passo seguinte é este: onde essa validação realmente acontece quando vários serviços publicam e consomem eventos ao mesmo tempo?
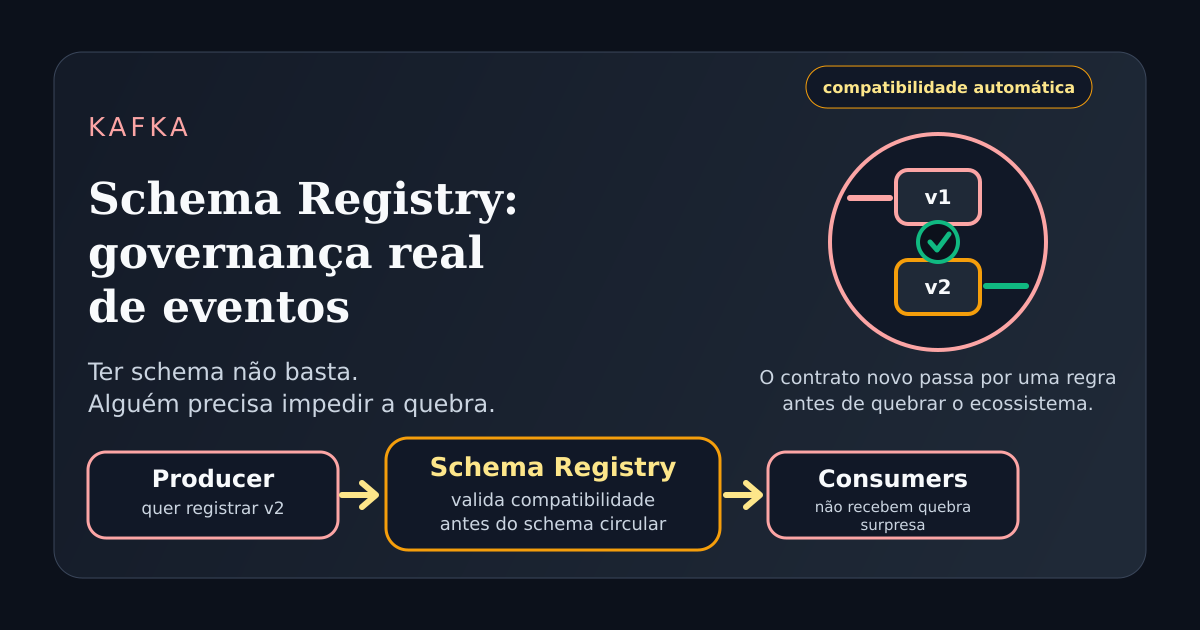
A resposta prática costuma ser Schema Registry.
Não porque ele "guarda schemas".
Mas porque ele coloca governança no fluxo real de publicação e evolução do contrato.
O problema de ter schema sem controle central
Muita gente melhora bastante quando troca JSON informal por Avro, Protobuf ou outro formato com schema.
Só que existe uma armadilha aí.
O time passa a ter schema, mas continua sem governança.
Na prática, isso costuma significar:
- cada serviço versiona contratos do próprio jeito
- não existe uma fonte central para saber qual schema está valendo
- a compatibilidade é discutida na review, mas não verificada automaticamente
- mudanças perigosas só aparecem quando algum consumer recebe o evento
Esse é o ponto crítico.
Sem controle central, schema vira documentação executável local. Não vira política operacional compartilhada.
O producer pode mudar um campo obrigatório, renomear um atributo ou alterar um tipo acreditando que "ninguém usa mais isso". O deploy sobe. O tópico continua ativo. E a quebra aparece distribuída, em consumidores diferentes, muitas vezes horas depois.
É a mesma lógica que já apareceu nos posts sobre schema como contrato e evolução segura: o problema não é apenas mudar. O problema é mudar sem uma regra central que consiga impedir a quebra antes que ela entre no tópico.
O que o Schema Registry faz de verdade
Schema Registry não é só um repositório de arquivos .avsc.
Ele funciona como a referência central dos contratos usados pelos eventos.
Em vez de cada serviço carregar uma noção isolada de "qual é o schema atual", existe um lugar único onde versões são registradas, consultadas e validadas.
Isso muda bastante a operação do ecossistema:
- o schema passa a ter histórico centralizado
- producers deixam de publicar contratos novos sem registro formal
- consumers conseguem resolver a versão correta do contrato
- regras de compatibilidade deixam de depender apenas de disciplina manual
Na prática, o registry transforma schema em ativo governado.
Sem ele, você pode até ter contratos bem escritos.
Com ele, você passa a ter uma forma automática de controlar se a próxima mudança ainda respeita o ecossistema que já existe.
Como validar mudanças antes de ir para produção
Esse é o ganho mais importante.
Quando um producer tenta registrar uma nova versão de schema, o registry pode verificar se aquela mudança respeita a política de compatibilidade definida para aquele subject.
Se a regra for BACKWARD, por exemplo, a nova versão precisa continuar conseguindo ler dados escritos pela versão anterior. Se a regra for FULL, a convivência precisa funcionar nos dois sentidos. Se você quiser revisar a lógica de cada modo, ela está detalhada no post sobre BACKWARD, FORWARD e FULL.
O efeito operacional disso é forte:
- remover um campo ainda necessário pode ser bloqueado
- trocar o tipo de um atributo pode falhar no registro
- exigir um novo campo obrigatório sem transição pode ser recusado
- mudanças aditivas compatíveis passam com muito mais segurança
Ou seja: a discussão deixa de ser "acho que não quebra".
Ela passa a ser "o contrato novo foi aceito ou rejeitado pela regra de compatibilidade".
Esse ponto reduz muito o risco de descobrir o erro tarde demais.
Em vez de a quebra aparecer quando um consumer antigo tentar desserializar o payload novo, a mudança já pode morrer no pipeline de desenvolvimento, no ambiente de homologação ou até no momento de registrar o schema.
É aqui que o insight principal fica bem concreto:
não basta ter schema. Você precisa garantir que ninguém quebre ele.
Como o registry evita quebra entre serviços
Em arquiteturas orientadas a eventos, producer e consumer quase nunca evoluem juntos.
Um serviço publica hoje. Outro só atualiza semana que vem. Um terceiro reprocessa histórico. Um quarto ainda está preso a uma versão antiga do contrato.
Sem um mecanismo central, essa defasagem entre versões vira risco permanente.
Com Schema Registry, a arquitetura ganha um guardrail objetivo.
O producer não depende apenas da própria boa intenção para publicar algo seguro. A nova versão precisa passar pela política de compatibilidade antes de começar a circular.
Isso reduz bastante três tipos de quebra comuns:
- consumer antigo deixando de entender eventos novos
- consumer novo falhando ao reler histórico do tópico
- times diferentes tomando decisões incompatíveis sobre o mesmo contrato
Esse é o ponto em que compatibilidade deixa de ser conceito e vira proteção operacional.
No post sobre BACKWARD, FORWARD e FULL, a pergunta era "compatível para quem?". Aqui a pergunta vira outra:
quem garante essa compatibilidade na hora em que o contrato tenta mudar?
Em produção, a resposta mais madura é: o registry, e não apenas a memória do time.
Como a compatibilidade automática realmente funciona
O detalhe importante é que o registry não olha para o código do seu serviço.
Ele olha para o contrato.
Quando uma nova versão é registrada, ela é comparada com a versão anterior ou com o conjunto de versões anteriores, dependendo do modo configurado.
É aí que entram políticas como:
BACKWARDFORWARDFULL- modos
transitive, quando a regra precisa valer contra mais do que apenas a última versão
Na prática, isso automatiza uma parte da governança que times normalmente tentam resolver com checklist, documentação e boa vontade.
Só que checklist falha.
Review falha.
Memória compartilhada falha.
Validação automática tende a falhar muito menos, porque ela roda sempre e aplica a mesma regra para todos os serviços.
Esse é o tipo de disciplina que faz diferença quando um tópico deixa de ser integração entre dois sistemas e passa a ser dependência de vários consumers, pipelines, analytics e reprocessamentos.
O que muda no fluxo de desenvolvimento
Quando o Schema Registry entra de verdade no processo, o fluxo do time muda.
Uma alteração de evento deixa de ser apenas mudança de classe ou serializer.
Ela passa a ser mudança de contrato.
Isso costuma puxar boas consequências:
- o schema entra na revisão técnica como artefato de primeira classe
- o pipeline consegue falhar antes do deploy por incompatibilidade
- o rollout entre producer e consumer passa a seguir a direção protegida pela regra escolhida
- a conversa entre times fica menos subjetiva
Isso não elimina a necessidade de modelagem cuidadosa.
Se o time mudar o significado de um campo mantendo nome e tipo, o registry talvez aprove a evolução estrutural e o domínio ainda assim seja quebrado.
Schema Registry resolve governança estrutural.
Ele não substitui governança semântica.
Mas essa distinção é importante justamente porque muita arquitetura falha antes mesmo da parte semântica: falha no básico, deixando mudanças incompatíveis passarem sem nenhum bloqueio automático.
Um cuidado importante: registry não corrige contrato ruim
Vale evitar uma ilusão comum.
Schema Registry não transforma automaticamente um evento mal modelado em um bom contrato.
Se o evento já nasceu refletindo detalhe interno do producer, com nomes ruins, semântica confusa ou fronteira de negócio mal definida, o registry vai apenas governar esse contrato ruim com mais disciplina.
Ou seja:
- ele ajuda a impedir quebra estrutural
- ele ajuda a versionar e rastrear evolução
- ele ajuda a automatizar compatibilidade
- ele não decide sozinho se o evento representa bem o domínio
Por isso a ordem correta das ideias importa:
- modelar o evento como contrato
- definir como esse contrato pode evoluir
- usar Schema Registry para garantir que a regra seja realmente aplicada
Sem esse terceiro passo, a governança fica fraca.
Mas sem os dois primeiros, você só formaliza um contrato ruim.
O ponto que vale fixar
Schema Registry é o momento em que schema deixa de ser intenção e vira controle operacional.
Ele centraliza versões, aplica compatibilidade e bloqueia mudanças perigosas antes que elas virem incidente distribuído.
Se vários serviços dependem dos mesmos eventos, governança de contrato não pode ficar espalhada em wiki, review ou combinado de time.
Em Kafka, ter schema é um começo.
Garantir automaticamente que ninguém quebre esse schema é o que separa contrato formal de governança real em produção.