Se o seu consumer parte da premissa de que cada evento chega uma única vez, ele já começou errado.
Em Kafka, duplicidade não é um acidente exótico. Ela é uma consequência normal de um modelo orientado a confiabilidade. Se o sistema prefere tentar de novo em vez de perder dados, você precisa estar pronto para processar a mesma mensagem mais de uma vez.
É por isso que idempotência não é detalhe de implementação. É parte do contrato do consumidor.
O problema real
Muita gente aprende Kafka como se a conversa terminasse em producer, broker e offset.
Mas o problema de produção aparece um passo depois:
- o evento foi processado
- o efeito colateral aconteceu
- o offset não foi confirmado a tempo
- o consumer reinicia
- a mesma mensagem volta
Se esse fluxo gera uma segunda cobrança, um segundo e-mail, uma segunda reserva ou um segundo disparo de integração, o bug não está no broker.
O bug está no fato de que o consumer não foi desenhado para lidar com repetição.
Duplicidade não quebra o modelo do Kafka
Na prática, Kafka trabalha muito bem com entrega at-least-once.
Tradução direta: é melhor entregar de novo do que correr o risco de perder.
Isso significa que a duplicidade faz parte do custo de um sistema que prioriza durabilidade e reprocessamento. O mesmo raciocínio aparece quando falamos de durabilidade e tolerância a falhas e de como commit automático pode mentir.
O erro é esperar semântica de "exatamente uma vez" em um ponto onde ela simplesmente não existe sozinha.
De onde a duplicidade vem
Os casos mais comuns são bem menos teóricos do que parecem:
- o consumer processa a mensagem, chama um banco ou API externa, mas cai antes do commit
- o broker reenfileira a leitura depois de um rebalance
- o producer retenta uma publicação em uma falha transitória
- o fluxo inteiro é reprocessado a partir de um offset antigo
O ponto importante é este: do ponto de vista do Kafka, reenviar pode ser o comportamento correto.
Do ponto de vista do seu negócio, processar o mesmo efeito duas vezes pode ser desastroso.
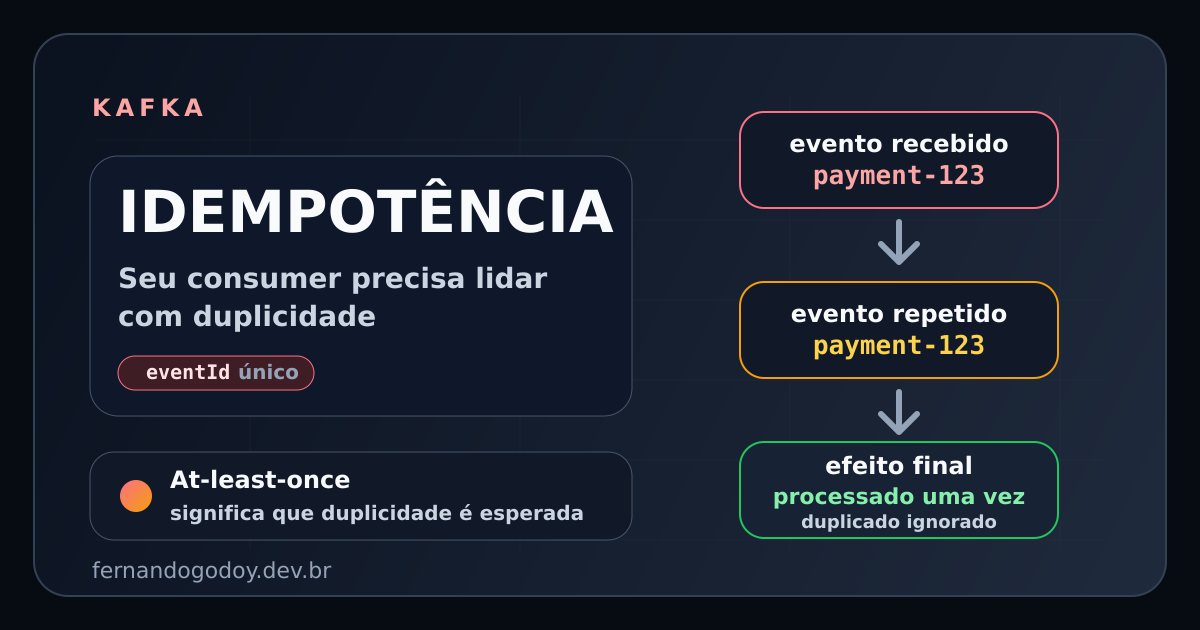
O que idempotência realmente significa
Idempotência não é "nunca receber duplicado".
Idempotência é receber duplicado e produzir o mesmo resultado final.
Se o mesmo evento entrar duas, três ou dez vezes, o estado final precisa continuar correto.
Exemplo:
- atualizar o status de um pedido para
PAGOé idempotente se repetir não muda nada além do que já estava feito - inserir uma cobrança nova a cada processamento não é idempotente
- enviar e-mail sem controle de chave de deduplicação não é idempotente
A pergunta certa não é "como evitar duplicidade no Kafka?".
A pergunta certa é: "se esse evento voltar, o meu consumer se comporta como sistema confiável ou como gatilho cego?".
O que não resolve
Tem algumas soluções que parecem suficientes, mas não são:
1. Confiar só no commit
Commit controla progresso de leitura.
Ele não desfaz efeito colateral já executado.
2. Guardar em memória
Se a deduplicação vive só na instância do consumer, ela morre no restart.
3. Apostar que enable.idempotence=true resolve tudo
Essa configuração ajuda do lado do producer.
Ela não torna idempotente uma escrita no banco, uma chamada HTTP ou um envio de notificação feito pelo consumer.
4. Fingir que duplicidade é rara
Em sistema distribuído, "raro" costuma significar "difícil de reproduzir, mas inevitável em produção".
Como tratar isso na prática
A forma mais comum de resolver é dar ao evento uma chave estável de idempotência e persistir essa referência no ponto onde o efeito real acontece.
Alguns padrões práticos:
- usar
eventIdouoperationIdcomo identificador único de processamento - manter tabela de eventos já processados com restrição única
- fazer
upsertem vez deinsertcego quando o modelo permitir - atrelar a deduplicação à operação de negócio, não só ao offset
Exemplo mental:
- se o evento diz "cobrança
payment-123foi aprovada" - o consumer precisa conseguir responder "eu já tratei
payment-123?" - se a resposta for sim, ele ignora o efeito duplicado e segue
O ganho real vem quando a deduplicação acontece junto do efeito persistente, não em uma checagem paralela frágil.
E o tal do exactly-once?
Esse ponto costuma confundir.
Kafka tem recursos para reduzir duplicidade em fluxos internos, principalmente em cenários de produce/consume dentro do próprio ecossistema Kafka.
Mas isso não elimina automaticamente duplicidade em efeitos externos.
Se o seu consumer grava em banco, chama gateway de pagamento ou dispara webhook, a responsabilidade continua sendo sua.
Exactly-once na infraestrutura não substitui idempotência na borda do negócio.
Quando isso vira obrigatório
Nem todo consumer precisa do mesmo rigor.
Mas em qualquer fluxo com dinheiro, estoque, contrato, notificação ou integração externa, tratar duplicidade como opcional é pedir incidente.
Se repetir um evento gera impacto real, idempotência deixou de ser melhoria técnica. Ela virou requisito funcional.
O ponto que vale fixar
Kafka não promete que o seu consumer verá cada evento uma única vez.
Ele te dá mecanismos para não perder dados e para reprocessar com segurança. O resto depende de como o consumidor reage quando o mesmo evento volta.
Idempotência é isso: aceitar que duplicidade existe e garantir que ela não quebre o negócio.