Retry parece uma boa ideia porque passa a sensação de insistência controlada.
Se uma chamada falhou, tenta de novo. Se o consumer não conseguiu processar, tenta mais uma vez. Se a dependência estiver instável, talvez a próxima tentativa funcione.
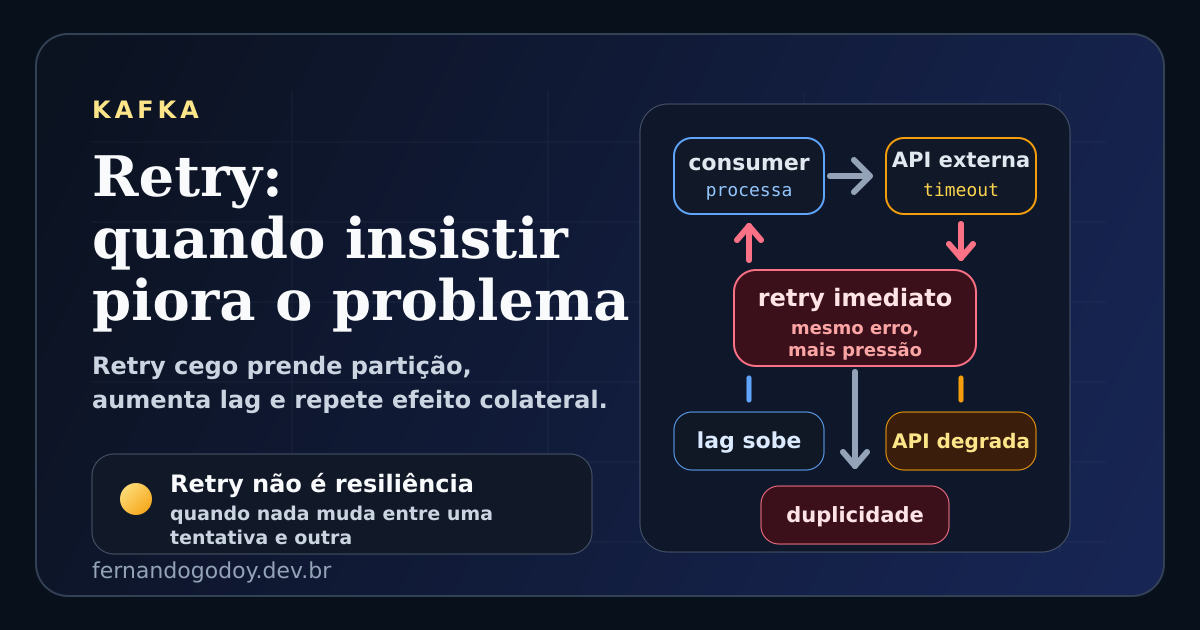
O problema é que retry cego costuma piorar exatamente o tipo de incidente que ele deveria aliviar.
Em Kafka, isso aparece o tempo todo: um consumer falha, repete a mesma mensagem em loop, segura a mesma partição, aumenta o lag, pressiona um banco já degradado e ainda corre o risco de repetir efeito colateral.
Retry não é automaticamente resiliência.
Muitas vezes, é apenas amplificação de falha.
O erro mais comum
O erro clássico é tratar toda falha como temporária.
Na prática, nem toda falha merece nova tentativa imediata.
Alguns exemplos:
- timeout em uma API externa pode ser transitório
429ou503pode pedir espera e redução de pressão- payload inválido não vai melhorar na quarta tentativa
- erro de validação de negócio não se cura sozinho
- constraint violation no banco pode indicar duplicidade ou modelagem errada, não falta de insistência
Esse é o ponto central: retry só faz sentido quando existe chance real de a próxima tentativa encontrar um contexto melhor que a anterior.
Se nada mudou, você não está recuperando.
Você só está repetindo custo.
Quando retry piora o Kafka
No ecossistema Kafka, retry mal desenhado costuma produzir três efeitos ruins ao mesmo tempo.
1. A partição fica presa
Se o consumer recebe um evento, falha e fica insistindo nele no mesmo loop, aquela partição para de progredir.
As mensagens seguintes ficam esperando atrás de um item que já se mostrou problemático.
O resultado aparece como lag crescendo.
E foi exatamente esse tipo de leitura enganosa que discutimos no post sobre lag alto não ser culpa automática do broker.
2. A dependência degradada recebe mais pressão
Se o problema está no banco, numa API externa ou num serviço interno lento, retry imediato vira ataque involuntário.
O sistema que já estava sofrendo passa a receber mais chamadas por unidade de tempo, vindas justamente do mecanismo que deveria ajudar na recuperação.
Em vez de absorver a falha, o consumer amplifica a sobrecarga.
3. O efeito colateral pode acontecer de novo
Se a falha acontece depois de parte do processamento ter sido executada, insistir sem idempotência pode duplicar efeito real de negócio.
Uma cobrança pode ser enviada duas vezes. Um e-mail pode ser disparado novamente. Um evento de saída pode ser republicado.
Foi por isso que o post anterior insistiu tanto em idempotência no consumer.
Retry sem idempotência é uma combinação perigosa.
Nem toda falha pede a mesma estratégia
O desenho maduro começa quando o time para de falar em "retry" como se fosse uma única coisa.
O que existe de verdade é classificação de falha.
Perguntas úteis:
- isso pode funcionar se eu tentar de novo daqui a alguns segundos?
- esse erro depende de carga, concorrência ou indisponibilidade temporária?
- esse evento está malformado e nunca vai funcionar?
- eu devo reprocessar depois ou desviar para análise?
- repetir agora aumenta ou reduz a chance de recuperação?
Sem essa classificação, o sistema cai em duas armadilhas:
- retry demais para erros permanentes
- abandono precoce para erros realmente transitórios
Os dois lados são ruins.
Mas, em produção, o mais destrutivo costuma ser o primeiro.
O loop que parece seguro e destrava incidente
Um exemplo comum:
- o consumer lê o evento
- chama uma API de pagamento
- recebe timeout
- tenta de novo imediatamente
- recebe timeout de novo
- segue tentando várias vezes dentro do mesmo processamento
Na superfície, isso parece prudente.
No efeito sistêmico, não.
Enquanto o consumer insiste:
- a partição não avança
- o grupo pode acumular backlog
- o tempo de processamento sobe
- a janela para rebalance aumenta
- a dependência externa continua pressionada
Se esse comportamento se espalha por várias instâncias, o retry deixa de ser local.
Ele vira padrão de carga do sistema inteiro.
E incidentes pequenos começam a escalar muito mais rápido.
Retry imediato é diferente de retry controlado
Vale separar bem duas coisas que muita gente mistura:
- repetir imediatamente no mesmo fluxo
- reencaminhar para uma nova tentativa com atraso, limite e observabilidade
O primeiro costuma ser o mais perigoso.
Ele bloqueia progresso, prende partição e reage à falha com mais pressa.
O segundo pode fazer sentido, desde que exista critério.
Alguns elementos saudáveis:
- limite máximo de tentativas
- backoff exponencial
- jitter para evitar sincronismo entre instâncias
- classificação entre erro transitório e erro permanente
- desvio para DLQ quando insistir deixa de ser racional
- métricas para enxergar volume de retries, taxa de sucesso após retry e impacto no lag
Retry que não tem limite nem observabilidade não é estratégia.
É reflexo.
Quando tirar a mensagem do caminho é a melhor decisão
Tem eventos que não deveriam continuar bloqueando a partição.
Se o payload está inválido, se há erro estrutural, se a regra de negócio não permite processamento ou se a mensagem exige intervenção humana, insistir ali só mascara o problema.
Nesses casos, a estratégia madura costuma ser:
- registrar o motivo da falha
- mover a mensagem para uma trilha de erro ou DLQ
- liberar a partição para o restante do fluxo
- tratar o evento problemático fora do caminho crítico
Isso não significa desistir da mensagem.
Significa parar de sacrificar o fluxo inteiro por um item que não vai melhorar sozinho.
Em muitos cenários, proteger a vazão e a estabilidade do consumo vale mais do que insistir cegamente na mesma unidade de trabalho.
Retry também precisa respeitar a semântica do negócio
Esse ponto costuma ser subestimado.
Mesmo quando a falha parece transitória, a repetição pode não ser neutra.
Se a operação envolve:
- cobrança
- reserva
- envio de notificação
- escrita em serviço externo
- publicação de evento derivado
então retry precisa vir acompanhado de garantias sobre duplicidade e consistência.
Não basta pensar "vai uma vez ou duas".
Você precisa pensar:
- se isso repetir, o estado final continua correto?
- existe chave de idempotência?
- existe outbox ou algum mecanismo para não perder nem duplicar publicação?
- a dependência externa aceita operação repetida com segurança?
Sem essas respostas, retry vira aposta.
O que costuma funcionar melhor na prática
Em arquiteturas Kafka mais maduras, o padrão costuma ser bem menos impulsivo.
Algo nessa linha:
- falhas claramente permanentes vão para DLQ ou trilha de tratamento
- falhas transitórias recebem retry com atraso e limite
- chamadas externas são protegidas com timeout, circuit breaker e backoff
- consumers são idempotentes para tolerar repetição
- reprocessamento fica desacoplado do caminho crítico quando necessário
Perceba a lógica.
O objetivo não é "tentar sempre".
O objetivo é tentar de um jeito que não destrua o restante do sistema.
Essa diferença parece pequena no discurso.
Em produção, ela separa recuperação de amplificação.
Retry mal configurado costuma gerar diagnóstico errado
Outro efeito ruim é observabilidade enganosa.
O time olha o painel e conclui:
- o broker está lento
- Kafka não está dando conta
- precisamos de mais partições
- precisamos escalar consumers
Só que, muitas vezes, o gargalo real é o próprio comportamento de retry.
Foi essa linha de raciocínio que já apareceu quando falamos de hot partition, rebalance e commit automático.
Kafka frequentemente recebe a culpa por sintomas que nasceram no desenho do consumer.
Retry cego é uma das causas mais comuns desse tipo de confusão.
O ponto que vale fixar
Retry não é virtude por si só.
Insistir sem critério pode aumentar lag, prolongar incidente, derrubar dependências e repetir efeitos que o negócio não aceita duplicar.
Em sistemas orientados a eventos, a pergunta correta não é "tem retry?".
É:
quando falha, o sistema sabe diferenciar o que vale tentar de novo daquilo que precisa sair do caminho?
Se não souber, o retry não está protegendo o fluxo.
Está piorando o problema.