Kafka resolve problemas reais.
Mas nem todo problema real precisa de Kafka.
Essa diferença parece óbvia no papel e desaparece rápido em reunião de arquitetura.
Alguém menciona desacoplamento.
Alguém fala em eventos.
Alguém lembra que o sistema pode crescer.
De repente, um fluxo que poderia ser uma chamada HTTP, uma tabela no banco ou uma fila simples ganha tópico, consumer group, schema, retry, DLT, observabilidade de lag, política de retenção, idempotência, reprocessamento, governança e operação de cluster.
Às vezes isso é exatamente o que o sistema precisa.
Às vezes é só complexidade entrando pela porta da frente com crachá de arquitetura moderna.
O objetivo deste post não é defender que Kafka é pesado demais ou que você deveria evitá-lo por padrão.
É o contrário: Kafka é uma ferramenta excelente quando o problema tem o formato certo.
Mas quando o problema não tem esse formato, o custo aparece do mesmo jeito e o benefício não vem na mesma proporção.
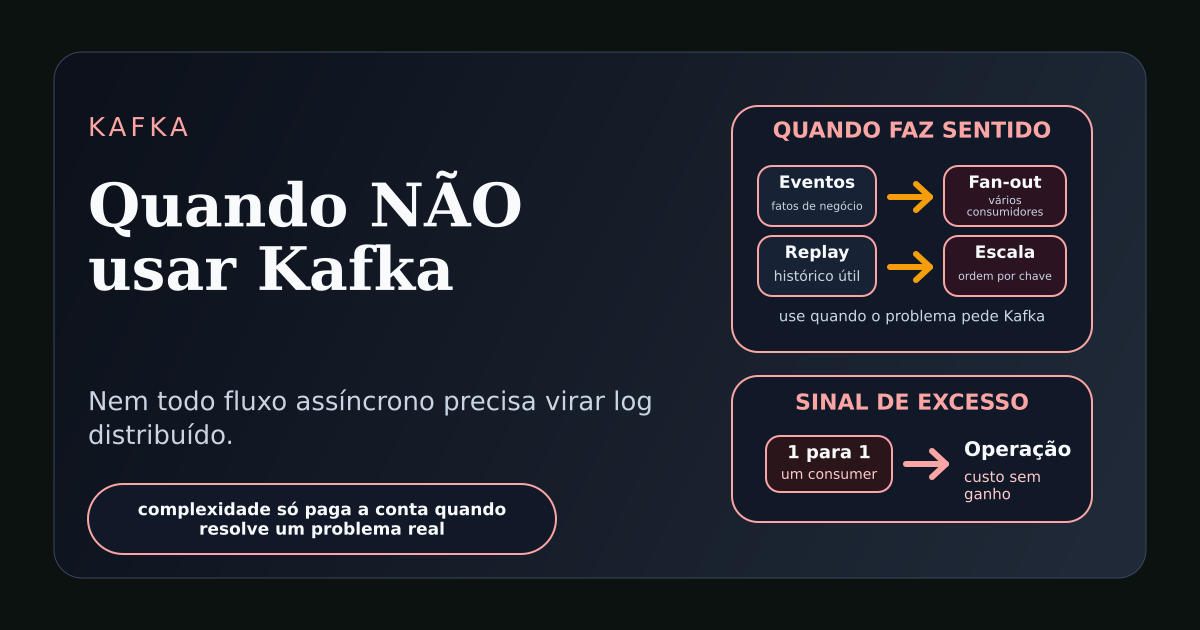
O primeiro sinal: existe apenas um produtor e um consumidor
Kafka brilha quando um fato publicado por um sistema pode interessar a vários consumidores, agora ou no futuro.
Um evento OrderCreated pode alimentar faturamento, estoque, antifraude, analytics, atendimento, notificação e projeções operacionais.
Nesse cenário, o produtor não deveria conhecer todos os interessados. O log de eventos vira um ponto de distribuição e cada consumidor evolui com alguma independência.
Mas se o seu fluxo é sempre:
- serviço A envia uma mensagem;
- serviço B processa;
- ninguém mais consome;
- não existe necessidade real de retenção longa;
- não existe reprocessamento relevante;
- não existe fan-out;
- não existe evolução independente de consumidores.
Então talvez você não tenha um problema de eventos.
Talvez você tenha uma integração ponto a ponto.
E integração ponto a ponto pode ser resolvida com HTTP, RPC, fila simples, job assíncrono, outbox com worker ou até uma tabela de controle, dependendo do caso.
Kafka ainda pode funcionar.
A pergunta é se ele está comprando algo que você realmente usa.
Se o tópico só substitui uma chamada direta por uma indireta, sem trazer distribuição, retenção, reprocessamento ou desacoplamento de verdade, o desenho ficou mais difícil de operar sem ficar muito mais capaz.
O segundo sinal: o fluxo precisa de resposta imediata
Kafka é assíncrono por natureza.
Isso é uma força quando o produtor não precisa esperar todos os efeitos acontecerem na hora.
O serviço publica um fato, confirma sua própria transação e outros serviços reagem depois.
Mas se a experiência do usuário ou a regra de negócio precisa de resposta imediata, o uso de Kafka pode virar uma simulação ruim de chamada síncrona.
O desenho começa assim:
- a API recebe uma requisição;
- publica um evento no Kafka;
- outro serviço consome;
- processa;
- publica outro evento;
- a API fica consultando estado, esperando callback ou segurando uma requisição aberta;
- o usuário espera como se tudo fosse síncrono.
Nesse ponto, a arquitetura está usando um meio assíncrono para implementar uma expectativa síncrona.
Às vezes isso faz sentido, principalmente quando o processo é longo e o usuário entende que o resultado virá depois.
Mas se o fluxo é curto, determinístico e precisa responder agora, uma chamada direta pode ser mais honesta.
O problema não é usar assíncrono.
O problema é fingir que assíncrono não muda o contrato do produto.
Quando Kafka entra no meio, você precisa lidar com estados intermediários: recebido, pendente, processando, falhou, expirado, compensado, concluído.
Se o domínio não precisa desses estados, talvez você esteja criando estados artificiais só para justificar a infraestrutura.
O terceiro sinal: você precisa de transação forte entre tudo
Um pedido clássico:
"quero publicar no Kafka, gravar no banco, chamar uma API externa e garantir que tudo aconteça exatamente uma vez".
Esse desejo é compreensível.
Também é um sinal de alerta.
Kafka tem garantias fortes dentro do seu próprio modelo, especialmente quando falamos de durabilidade, replicação, ordem por partição, commit de offset e transações Kafka para Kafka.
Mas Kafka não transforma automaticamente banco, API externa, gateway de pagamento, e-mail e sistema legado em uma única transação distribuída.
Se o seu requisito central é atomicidade rígida entre múltiplos recursos externos, Kafka talvez não seja o centro da solução.
Você ainda vai precisar pensar em:
- outbox;
- idempotência;
- deduplicação;
- compensação;
- reconciliação;
- retry com critério;
- estados de processo;
- rastreabilidade operacional.
Kafka pode participar muito bem desse desenho.
Mas ele não elimina o desenho.
Se a equipe está escolhendo Kafka porque espera que ele resolva a fronteira transacional do sistema inteiro, a expectativa está errada.
Esse ponto conversa diretamente com o post sobre exactly-once: a garantia é poderosa, mas tem escopo.
Fora desse escopo, idempotência continua sendo obrigação de arquitetura.
O quarto sinal: o volume não justifica a operação
Kafka aguenta muito volume.
Isso não significa que todo sistema com pouco volume deveria usá-lo "para estar preparado".
Preparação tem custo.
Mesmo em ambiente gerenciado, Kafka exige decisões que uma fila simples talvez não exija com a mesma intensidade:
- número de partições;
- chave de particionamento;
- retenção;
- compactação ou deleção;
- política de retry;
- DLT;
- schema;
- compatibilidade;
- observabilidade de lag;
- reprocessamento;
- controle de consumidores lentos;
- governança de tópicos;
- segurança e permissões;
- capacidade de investigar produção.
Se o sistema processa poucos eventos por minuto, tem baixa criticidade e não precisa de replay, múltiplos consumidores ou retenção, talvez o custo cognitivo seja maior do que o problema.
Isso não quer dizer que volume baixo proíbe Kafka.
Existem fluxos de baixo volume e alto valor em que Kafka faz sentido por auditabilidade, integração entre domínios ou desacoplamento estratégico.
O erro é usar volume futuro hipotético como argumento único.
"Um dia pode crescer" não é arquitetura.
É aposta.
Arquitetura precisa deixar claro qual problema existe hoje, qual problema é provável amanhã e quanto custa carregar a solução desde agora.
O quinto sinal: você não quer replay
Um dos grandes diferenciais do Kafka é que mensagens não desaparecem assim que são consumidas.
Elas ficam no log durante o período de retenção.
Isso permite reprocessar, criar novos consumidores, reconstruir projeções e auditar eventos passados.
Mas esse poder só tem valor se o domínio consegue conviver com replay.
Reprocessar evento não é apertar um botão inocente.
Se o consumer envia e-mail, cobra cartão, reserva estoque, dispara webhook ou altera estado de forma não idempotente, replay pode causar dano.
Para usar bem Kafka, você precisa desenhar consumidores que entendem duplicidade e reprocessamento.
Se a sua equipe não pretende reprocessar, não quer manter histórico, não precisa criar novos consumidores a partir de eventos antigos e não está preparada para idempotência, talvez o log retenível não esteja sendo usado como diferencial.
Nesse caso, você está pagando por uma característica forte do Kafka e tratando-a como se fosse uma fila descartável.
Kafka pode ser usado como fila.
Mas quando ele é usado apenas como fila, vale perguntar se uma fila não resolveria com menos superfície operacional.
O sexto sinal: o evento não é um fato de negócio
Kafka funciona melhor quando o tópico carrega fatos relevantes para o domínio.
PaymentAuthorized.
InvoiceIssued.
CustomerUpdated.
InventoryReserved.
Esses nomes indicam algo que aconteceu e que pode interessar a outros contextos.
O sinal ruim aparece quando os eventos parecem comandos internos disfarçados:
ExecuteStepTwo;CallBillingService;UpdateTableX;ProcessPayload;ContinueFlow;SendToConsumerB.
Isso normalmente indica que Kafka está sendo usado como encanamento técnico entre pedaços de implementação, não como contrato de integração entre domínios.
O produtor continua sabendo demais sobre o consumidor.
O consumidor continua dependendo demais da intenção interna do produtor.
Só que agora essa dependência passa por tópico, offset e serialização.
Se o evento não significa nada fora do fluxo interno que o criou, talvez ele não seja um evento de integração.
Talvez seja apenas uma chamada de método distribuída.
E chamada de método distribuída é uma das formas mais caras de acoplamento quando ninguém assume que ela existe.
O sétimo sinal: a equipe não consegue operar o que está criando
Kafka em produção não termina quando o producer publica e o consumer lê.
Esse é só o começo.
Alguém precisa responder perguntas como:
- qual consumer está atrasado?
- esse lag é problema ou comportamento esperado?
- posso reprocessar este tópico sem duplicar efeito de negócio?
- por que essa partição está mais quente?
- quem é dono deste tópico?
- que contrato governa esse payload?
- posso remover este campo?
- o que acontece quando o consumer falha por três horas?
- como recuperar mensagens enviadas para a DLT?
- quando aumentar partições quebra ordem?
Se ninguém sabe responder, Kafka deixa de ser infraestrutura e vira fonte de incidentes opacos.
Isso não é uma crítica à equipe.
É uma característica da ferramenta.
Kafka exige maturidade operacional porque ele desloca parte da complexidade do request/response para o mundo de logs, offsets, partições, consumidores e consistência eventual.
Quando a equipe ainda não tem observabilidade, runbooks, padrões de schema, estratégia de retry e clareza de ownership, talvez a primeira entrega devesse ser mais simples.
Ou talvez Kafka entre, mas com escopo menor, em um fluxo onde o aprendizado não compromete o coração do negócio.
O oitavo sinal: você só quer "desacoplar"
"Desacoplar" é uma palavra perigosa porque parece sempre positiva.
Mas desacoplamento não é um estado binário.
Você pode remover acoplamento temporal e criar acoplamento operacional.
Pode remover chamada direta e criar dependência de contrato.
Pode evitar disponibilidade simultânea entre serviços e criar consistência eventual que o produto não estava preparado para explicar.
Pode tirar uma dependência do código e colocá-la no processo de suporte.
Kafka desacopla algumas coisas e acopla outras.
Ele reduz a necessidade de produtor e consumidor estarem disponíveis ao mesmo tempo.
Ele facilita múltiplos consumidores.
Ele permite retenção e replay.
Ele cria um log de fatos compartilhado.
Mas ele também exige contrato de evento, governança, compatibilidade, versionamento, idempotência, monitoramento e entendimento de ordem por partição.
Se a justificativa para usar Kafka cabe apenas na frase "para desacoplar", ainda falta arquitetura.
A pergunta melhor é:
que tipo de acoplamento estamos tentando reduzir, e qual acoplamento aceitamos introduzir no lugar?
Alternativas que deveriam estar na mesa
Não usar Kafka não significa voltar para arquitetura ingênua.
Muitas vezes, a alternativa correta é mais simples e mais adequada.
Algumas opções:
- chamada HTTP síncrona quando o fluxo precisa de resposta imediata;
- fila gerenciada simples quando existe trabalho assíncrono ponto a ponto;
- banco com tabela de tarefas quando o problema é interno e controlado;
- outbox quando o desafio é publicar eventos após uma transação local;
- scheduler quando o processo é periódico;
- webhook quando a integração é externa e orientada a notificação;
- CDC quando a fonte de verdade já está no banco e o evento precisa refletir mudança persistida;
- workflow engine quando o problema central é coordenação de processo.
Nenhuma dessas opções é universal.
Todas têm custo.
Mas colocar alternativas na mesa evita a escolha automática.
Kafka deveria vencer por aderência ao problema, não por prestígio técnico.
Quando Kafka é uma boa escolha
Kafka começa a fazer muito sentido quando vários sinais aparecem juntos:
- eventos representam fatos de negócio relevantes;
- múltiplos consumidores precisam reagir de forma independente;
- retenção e replay têm valor real;
- ordem por chave importa;
- throughput ou volume futuro justificam particionamento;
- consumidores podem evoluir sem alterar produtores;
- o domínio tolera consistência eventual;
- existe maturidade para operar lag, schema, retry, DLT e reprocessamento;
- o histórico de eventos ajuda auditoria, reconstrução ou integração.
Nesses cenários, Kafka não é excesso.
É fundação.
Ele permite que sistemas diferentes conversem por fatos, que novos consumidores surjam com baixo atrito e que o passado continue disponível para reprocessamento e análise.
Mas repare: a decisão não vem de uma frase genérica.
Ela vem de propriedades concretas do problema.
Um checklist honesto antes de criar o tópico
Antes de adicionar Kafka ao desenho, vale responder sem pressa:
- quem são os produtores?
- quem são os consumidores?
- haverá mais de um consumidor independente?
- o evento é um fato de negócio ou um comando técnico?
- precisamos de retenção?
- precisamos de replay?
- duplicidade é aceitável?
- o consumer é idempotente?
- existe necessidade de ordem por chave?
- qual chave define essa ordem?
- o domínio tolera consistência eventual?
- o produto sabe lidar com estado pendente?
- como investigamos falhas?
- quem é dono do tópico?
- como o contrato evolui?
- qual alternativa mais simples foi considerada?
Se várias respostas forem vagas, o problema ainda não está maduro para Kafka.
Talvez esteja maduro para desenho.
E isso é uma etapa real do trabalho de arquitetura.
O custo que não aparece no diagrama
Diagramas de arquitetura costumam mostrar Kafka como uma caixa elegante no meio.
Producer de um lado.
Consumer do outro.
Setas bonitas.
O custo real fica fora da imagem:
- plantão investigando lag;
- consumer que confirmou offset antes de concluir efeito;
- DLT cheia sem processo de recuperação;
- evento sem dono;
- schema quebrando consumidor antigo;
- replay duplicando cobrança;
- partição mal escolhida limitando escala;
- fluxo de negócio espalhado em tópicos e consumidores;
- suporte tentando entender onde uma solicitação parou.
Nada disso torna Kafka ruim.
Só torna a decisão mais séria.
Ferramentas poderosas cobram clareza.
Quando a clareza não existe, a ferramenta não compensa.
Ela amplifica.
Conclusão
Kafka não deveria ser a resposta automática para "precisamos integrar sistemas".
Ele deveria ser a resposta para problemas em que log distribuído, retenção, replay, fan-out, ordem por chave, desacoplamento temporal e processamento assíncrono têm valor concreto.
Se o fluxo é simples, síncrono, ponto a ponto, sem replay, sem múltiplos consumidores, sem necessidade de retenção e sem maturidade operacional, Kafka pode transformar uma integração comum em um sistema distribuído difícil de explicar.
O sinal mais importante é este:
se você não consegue dizer claramente o que Kafka está comprando para o seu domínio, provavelmente está comprando complexidade.
E complexidade sem necessidade é dívida técnica com aparência de arquitetura.