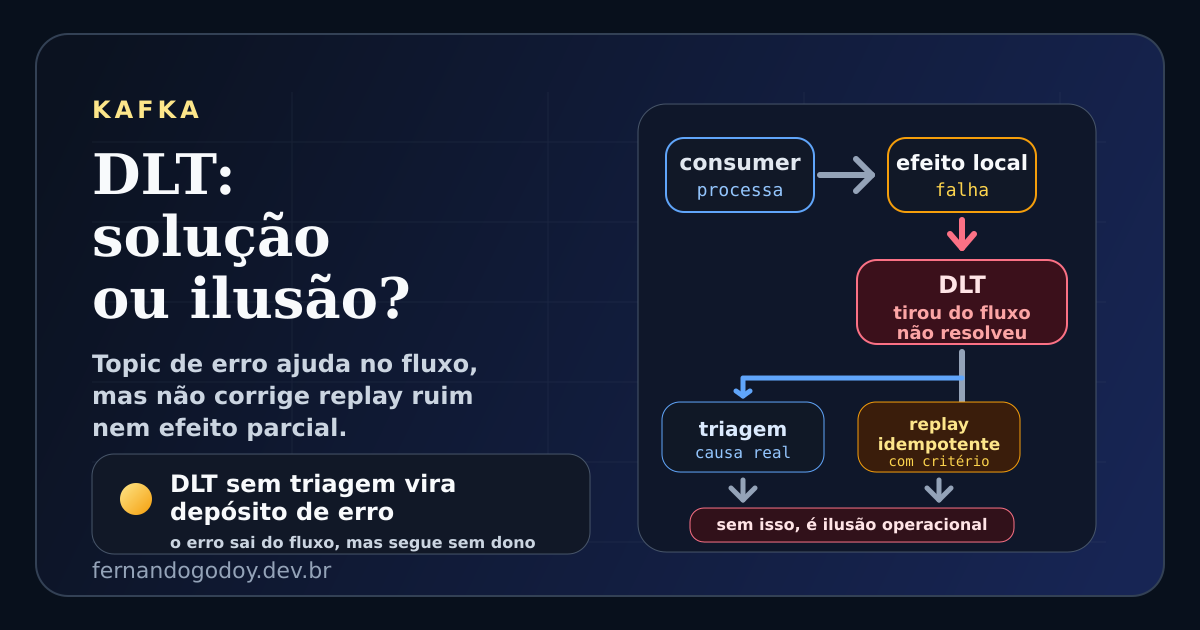
Tem fluxo que parece robusto porque "tem DLT".
A aplicação falha, a mensagem vai para outro tópico, o consumo principal continua andando e o time sente que o problema ficou contido.
Mas, algum tempo depois, a conta chega.
A DLT cresce sem dono, ninguém sabe qual erro ainda faz sentido reprocessar, parte dos eventos ficou sem efeito de negócio e o sistema passa a conviver com uma trilha paralela de pendências mal resolvidas.
No Kafka, esse nome é mais preciso do que DLQ.
O destino da mensagem é um topic, não uma queue.
No post sobre retry, o ponto era que insistir sem critério pode piorar produção. A DLT entra exatamente nessa conversa: quando ela aparece como resposta genérica para qualquer falha, o sistema para de corrigir causa e passa a administrar sintoma.
O que a DLT resolve de verdade
DLT resolve uma coisa importante: ela separa a mensagem que falhou do fluxo principal.
Isso evita que um registro problemático bloqueie indefinidamente o consumo normal do tópico.
Em alguns cenários, esse isolamento é valioso:
- payload malformado
- evento com schema incompatível
- dado inválido para a regra de negócio
- falha que precisa de análise manual antes de qualquer replay
Nesses casos, mandar a mensagem para uma trilha separada pode ser a decisão certa.
O ponto importante é não exagerar o que isso significa.
DLT não corrige o evento.
DLT não executa o efeito de negócio que ficou faltando.
DLT não reconcilia estado parcial.
DLT não transforma arquitetura frágil em fluxo resiliente.
Ela apenas impede que o problema continue misturado com o caminho principal.
Onde a ilusão começa
A ilusão começa quando a presença de uma DLT é tratada como sinônimo de confiabilidade.
Esse é um erro comum porque o sistema continua "rodando".
O consumer principal segue consumindo. O lag pode até parecer saudável. Os dashboards continuam verdes.
Só que o efeito real foi deslocado:
- a mensagem saiu do fluxo principal
- o problema foi empurrado para outro tópico
- a operação agora depende de alguém olhar, classificar e decidir o que fazer
Se isso não estiver desenhado com clareza, a DLT vira depósito de erro.
E depósito de erro não é estratégia de processamento.
Em muitos times, a conversa para cedo demais: "se der problema, vai para DLT".
Mas essa frase esconde perguntas que realmente importam:
- quais erros merecem retry antes da
DLT? - quais erros devem ir direto para quarentena?
- quais eventos podem ser descartados sem violar regra de negócio?
- quem observa a
DLT? - quem decide replay?
- o replay é idempotente?
- o fluxo downstream aguenta reprocessamento tardio?
Sem essas respostas, a DLT só troca falha imediata por dívida operacional.
Nem toda falha deveria ir para DLT
Um erro transitório de infraestrutura nem sempre deveria terminar em DLT.
Se o banco caiu por alguns segundos, se a API externa respondeu 503 ou se houve instabilidade passageira de rede, talvez o problema seja de retry controlado, backoff e proteção de dependência.
Nesses casos, jogar rapidamente para DLT pode ser só uma forma de desistir cedo demais.
Por outro lado, erro estrutural de contrato pode não merecer retry quase nenhum.
Se o payload chegou inválido, se o schema não bate, se um campo obrigatório simplesmente não existe ou se a regra rejeita aquele evento por inconsistência de dado, insistir várias vezes antes de mandar para DLT só gasta recurso.
Esse é o ponto central:
DLT só faz sentido quando ela faz parte de uma classificação clara de falhas.
Sem isso, o sistema começa a tratar todo erro da mesma forma. E erro de contrato, indisponibilidade temporária e bug de código raramente pedem a mesma resposta.
O risco mais caro: achar que DLT evita perda
Esse é um dos enganos mais perigosos.
A mensagem ter ido para DLT não significa que o fluxo de negócio ficou protegido.
Se o consumer:
- chamou um sistema externo
- gravou parte do estado
- falhou no meio
- ou publicou efeito parcial antes de mandar o evento problemático para
DLT
então o sistema já saiu do estado ideal.
A DLT só registra que houve problema naquele ponto.
Ela não desfaz efeito colateral. Ela não garante atomicidade. Ela não recompõe o que ficou pela metade.
Em outras palavras: DLT ajuda a não perder rastreabilidade da falha. Mas isso é diferente de garantir consistência do fluxo.
Essa diferença é importante porque muita arquitetura parece segura no diagrama e frágil na execução real.
Quando a DLT ajuda de verdade
Ela ajuda quando o time trata a DLT como mecanismo operacional, não como desculpa arquitetural.
Na prática, isso costuma exigir alguns cuidados:
- critérios claros para decidir entre retry, descarte controlado e
DLT - observabilidade real sobre volume, tipo de erro e idade das mensagens paradas
- procedimento explícito de triagem e replay
- replay idempotente
- distinção entre erro temporário e erro permanente
Também ajuda quando a DLT preserva contexto suficiente para investigação:
- payload original
- motivo da falha
- stack ou categoria do erro
- timestamp
- tentativas já realizadas
- metadados que permitam reconstruir o caminho do evento
Sem isso, a DLT vira só outro tópico com mensagens opacas esperando alguém adivinhar o que aconteceu.
O replay também pode piorar o sistema
Outro ponto que costuma ser subestimado é o replay.
Muita equipe desenha a DLT, mas não desenha o retorno dela.
E é justamente aí que o caos aparece.
Reprocessar tudo cegamente pode:
- repetir efeito colateral
- reabrir incidentes já mitigados
- inundar dependências frágeis
- recolocar no fluxo mensagens que continuam inválidas
Se o replay não for seletivo, auditável e idempotente, a DLT vira só um mecanismo de duplicar problema mais tarde.
Por isso, em muitos cenários, replay não deveria ser um "manda tudo de volta para o tópico original".
Ele deveria ser uma operação consciente.
Às vezes com correção de dado. Às vezes com filtro. Às vezes com intervenção manual. Às vezes, inclusive, com decisão explícita de não reprocessar.
O ponto que vale fixar
DLT pode ser solução.
Mas só quando ela entra como parte de uma estratégia maior de tratamento de falha.
Sozinha, ela também pode ser ilusão:
- mascara perda de efeito de negócio
- adia decisão difícil
- acumula dívida operacional
- dá sensação de robustez sem corrigir a causa
Se o seu fluxo depende de DLT, a pergunta certa não é "tem tópico de erro?".
A pergunta certa é:
o que acontece depois que a mensagem cai lá?
Se essa resposta não estiver clara, a DLT provavelmente ainda está mais perto de ilusão do que de solução.